什么是向量数据库? 简单下个定义,因为喂给Transformer的知识首先需要做embedding,所以用于存 […]
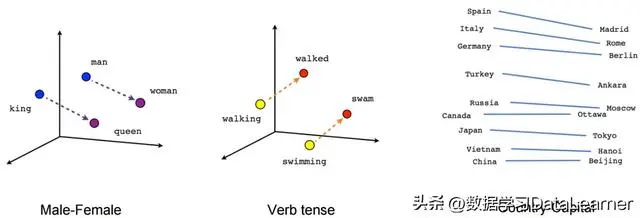
Embeddings技术简介及其历史概要 Embedding的主要价值在哪里? Embedding在大模型中的 […]
BERT的全称为Bidirectional Encoder Representation from Trans […]
1.介绍 Deep contextualized word representations获得了NAACL 2 […]
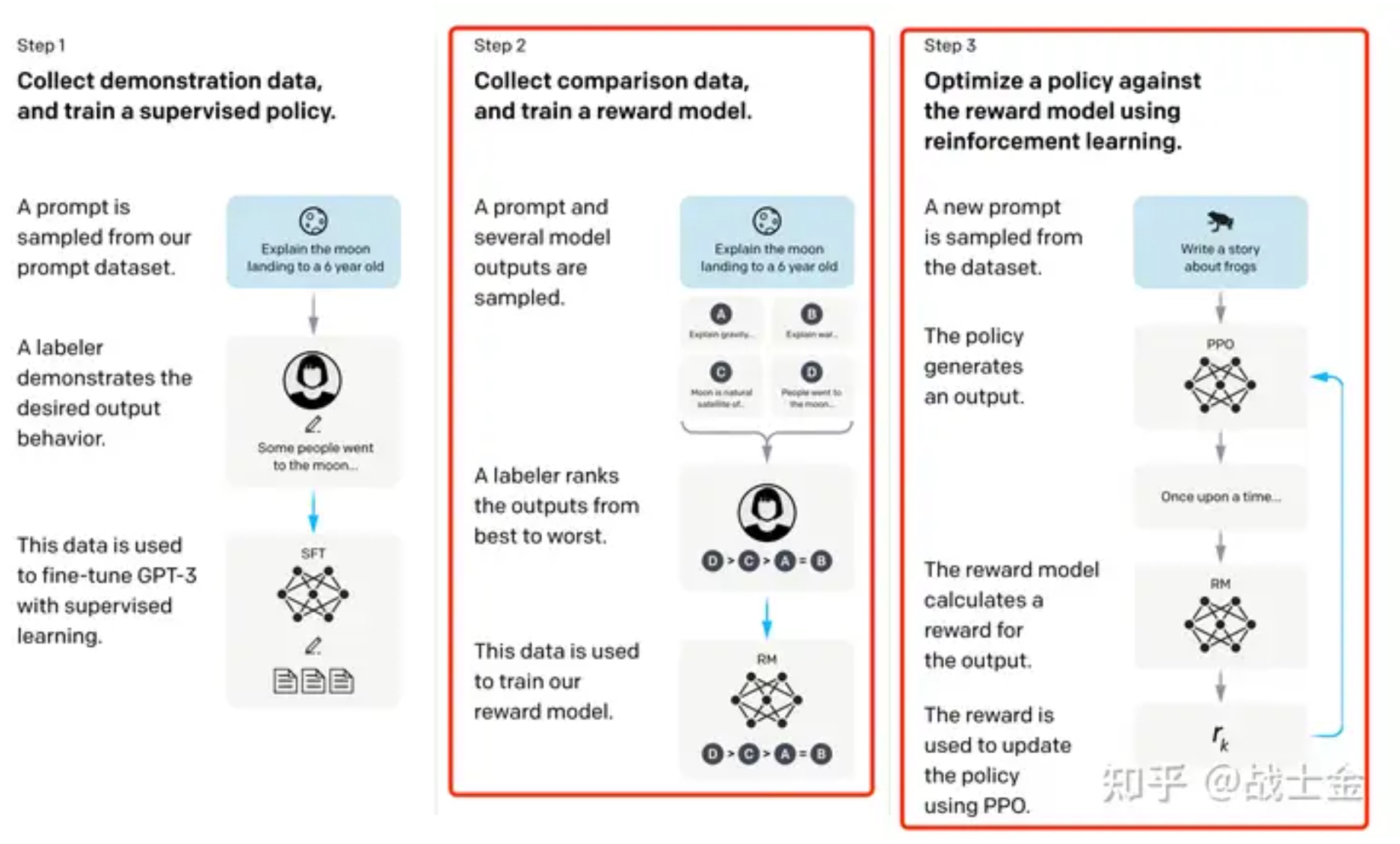
出自:https://zhuanlan.zhihu.com/p/624589622 一直都特别好奇大模型的强化 […]
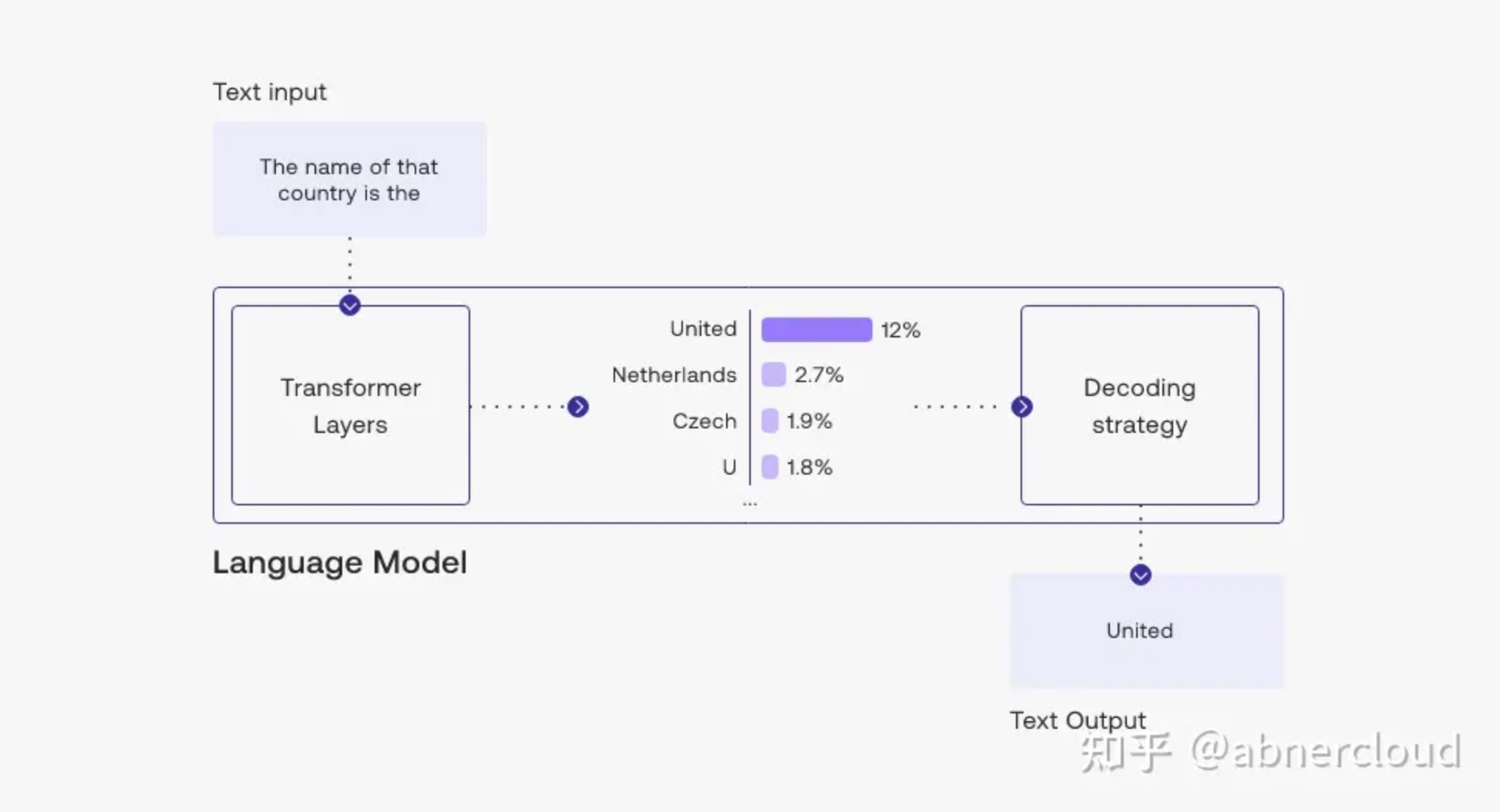
Top-k & Top-p 选择输出标记的方法是使用语言模型生成文本的一个关键概念。有几种方法(也称为 […]
一、MetaAI开源的OPT - Open Pre-trained Transformer模型 二、Googl […]
上下文窗口(context window)是指语言模型在进行预测或生成文本时,所考虑的前一个词元(token) […]
A thought-provoking conceptual artwork exploring the th […]
风景类提示词 Tropical beach scene in geometric aesthetics, jo […]
建筑物提示词 Picture a gleaming, translucent structure, suspe […]
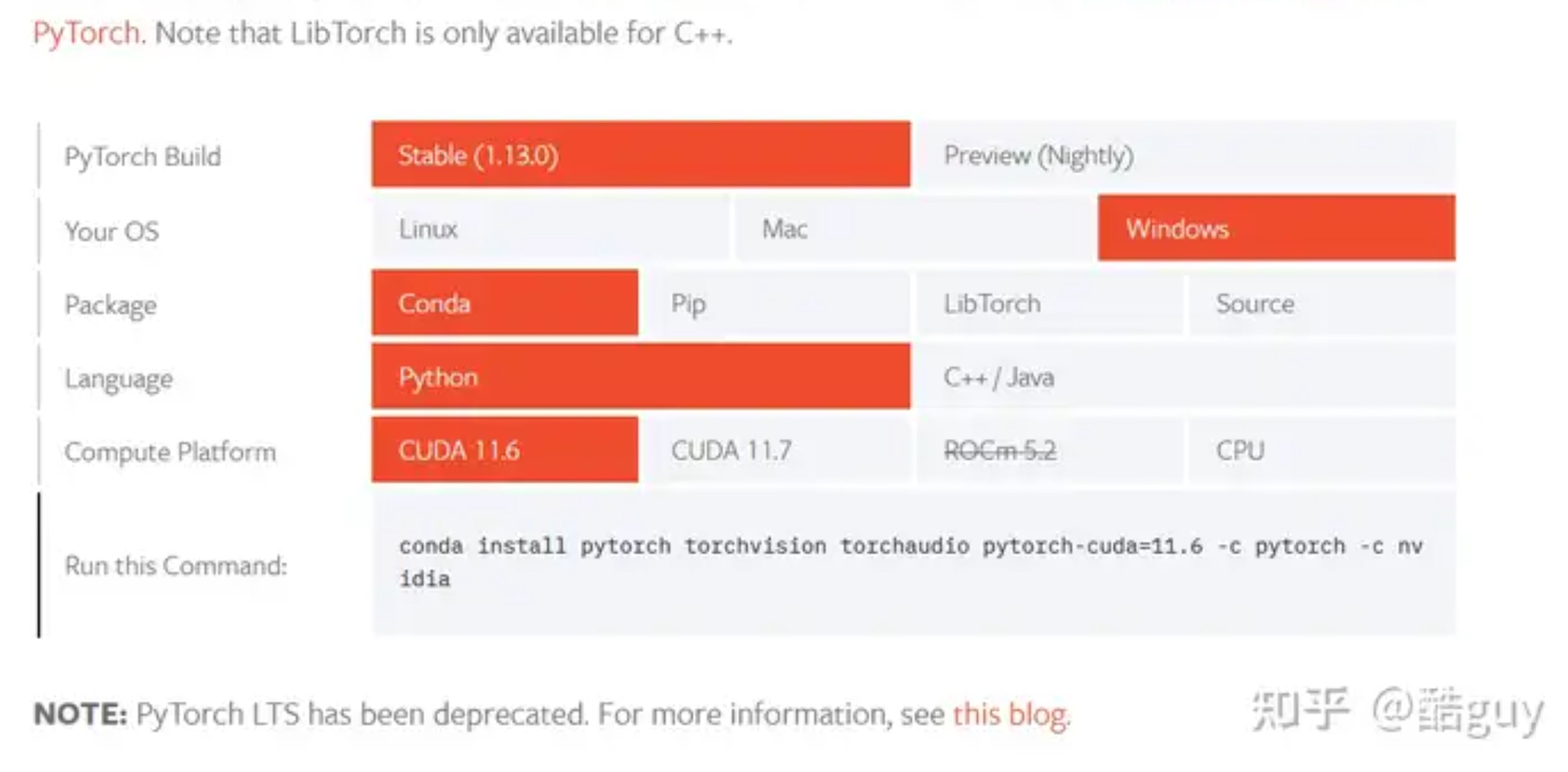
1. 检测方法 在cmd中进入自己的Python环境,输入: >>> import torc […]
ModelScope的简介 汇聚机器学习领域中最先进的开源模型,为开发者提供简单易用的模型构建 […]
目前 Stable Diffusion 主要有四种模型训练方法:Dreambooth、LoRA、Textual […]
很多时候,我们希望监控一些最新信息,能够第一时间在微信上看到。现在有很多这方面的消息推送工具,比如wxpush […]
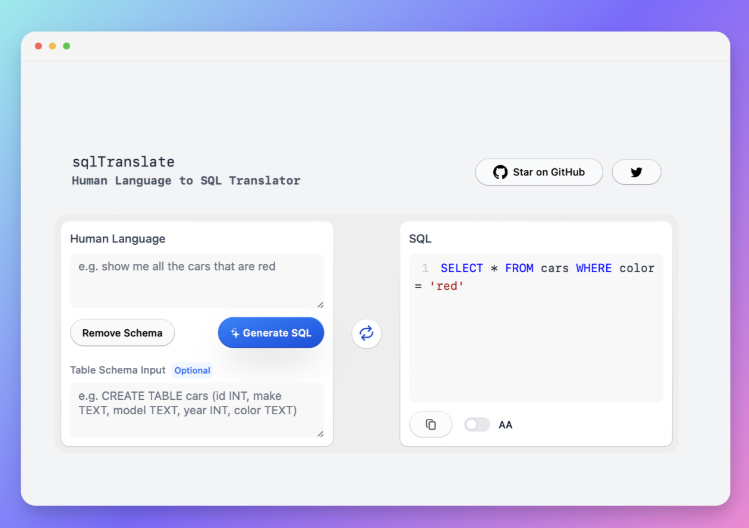
推荐一个Github上Start超过3.4K,可将自然语言转化为SQL语句的开源项目。 项目简介 这是一个利用 […]
1.预训练阶段(Pretraining Stage) 工欲善其事,必先利其器。 当前,不少工作选择在一个较强的 […]
No.1 MSRA-TD500 (MSRA Text Detection 500 Database) 下载链接 […]
从严格定义来看,学字符识别(Optical Character Recognition, OCR)是指对文本资 […]
一、OCR是什么? 光学字符识别(Optical Character Recognition, OCR)是指对 […]
就在刚刚,王小川的开源大模型又有了新动作—— 百川智能,正式发布130亿参数通用大语言模型(Baichuan- […]
出自:https://zhuanlan.zhihu.com/p/634608422 目前已囊括19个大模型,覆 […]
对于大模型prompt的设计,近期斯坦福吴恩达伙同OpenAl出了一套视频教程(B站地址:https://ww […]
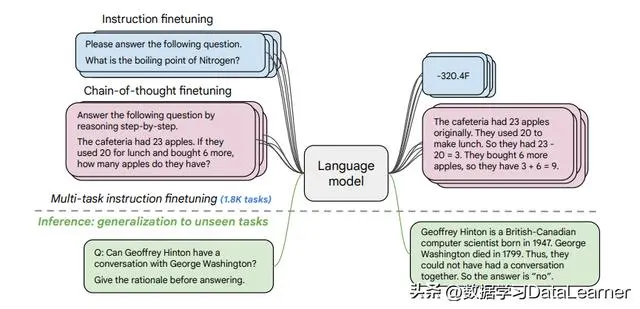
Tuning整体介绍 微调(Fine-tunning) 语言模型的参数需要一起参与梯度更新 轻量微调(ligh […]
原文:https://zhuanlan.zhihu.com/p/635710004 1. 开源基座模型对比 大 […]
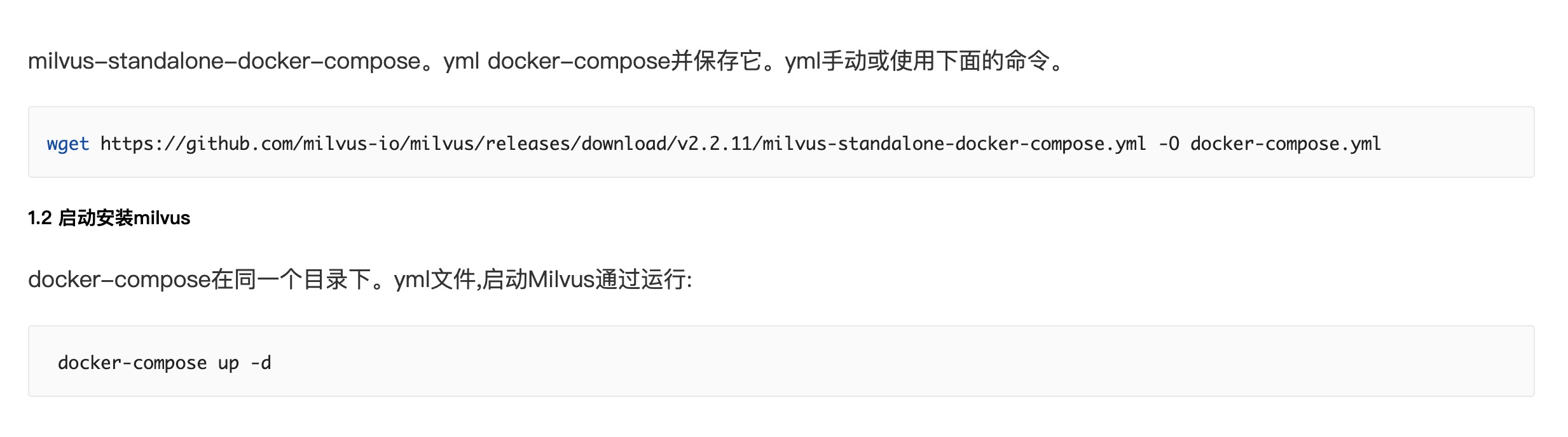
1.安装 目前官方提供 单机模式、集群模式、离线模式三种安装方式,目前milvus都是基于docker 容器方 […]
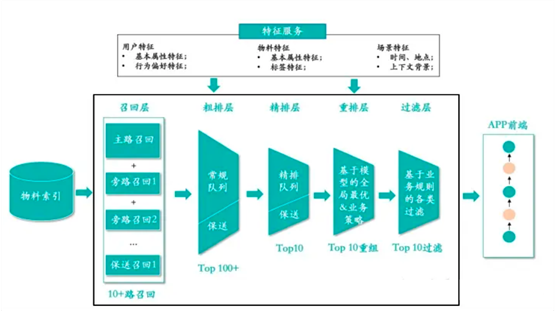
需求描述 打造 特定领域知识(Domain-specific Knowledge) 问答 系统,具体需求有: […]
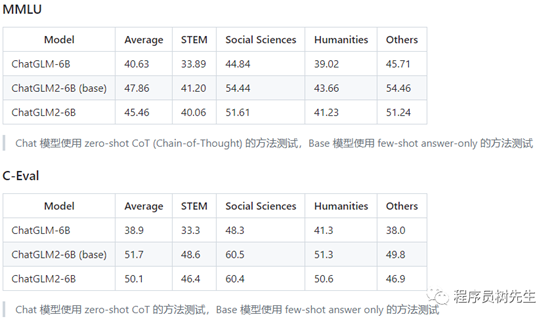
ChatGLM2-6B 介绍 ChatGLM2-6B 在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基 […]
来源|阿里开发者公众号https://developer.aliyun.com/article/1272112 […]













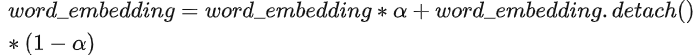
什么是向量数据库? 简单下个定义,因为喂给Transformer的知识首先需要做embedding,所以用于存 […]