我需要一些适合父亲旅行的父亲节礼物建议,例如行李箱、旅行背包、户外装备等。 父亲节即将来临,我想为爸爸准备一份 […]
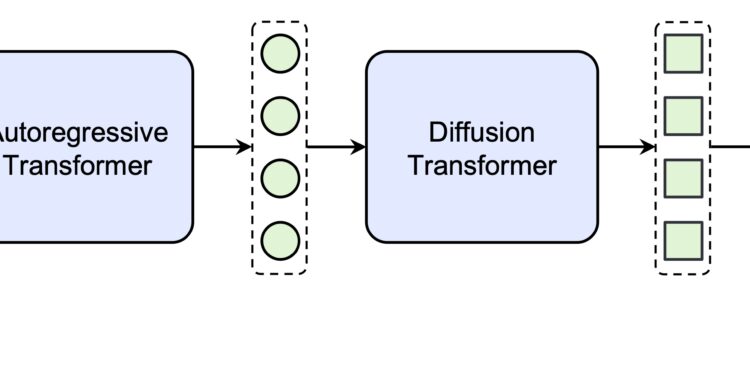
Seed-TTS 是由字节跳动开发的一种高级文本到语音(TTS)模型系列,能够生成高质量、几乎无法与人类语音区 […]
Mobile-Agent 是一个旨在帮助用户更高效地操作移动设备的项目。该项目通过多种技术手段,实现了对移动设 […]
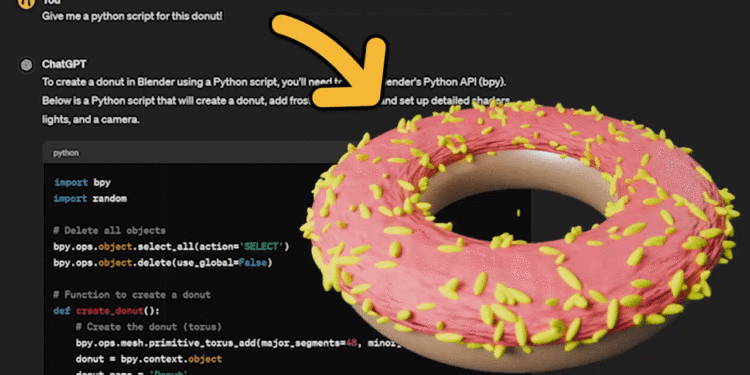
在这篇教程中,我们将展示如何使用ChatGPT生成的Python脚本在Blender中创建3D场景。我们将以一 […]
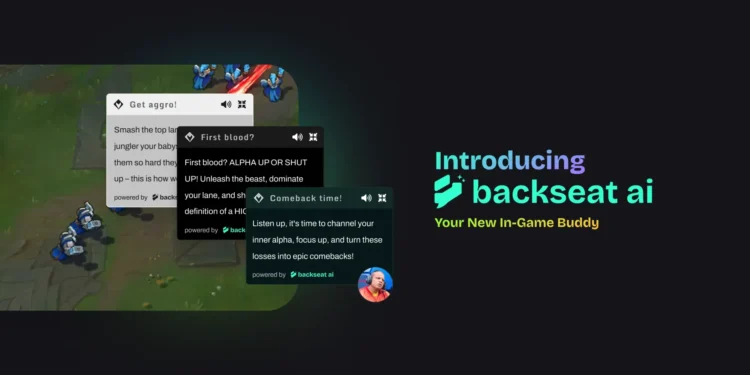
Backseat AI 是一个免费的、Riot 批准的英雄联盟 AI 伴侣,在比赛过程中,通过语音为玩家提供实 […]
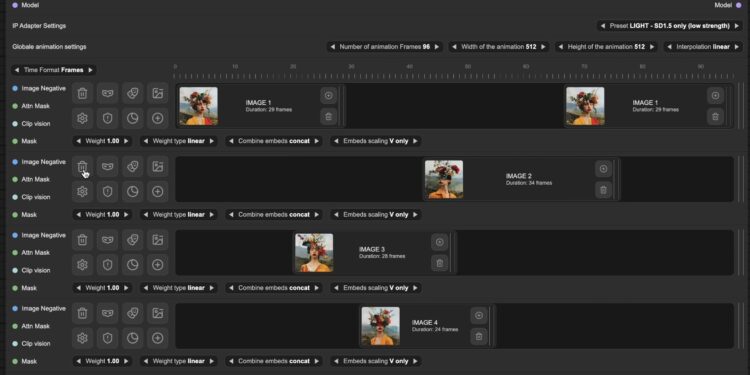
TimeUi 是一个用于 ComfyUi 的时间线节点系统,它的作用类似于视频或动画编辑工具中的时间线功能。用 […]
1.安装Python 和 git环境,python需要 3.9+ 版本,比如我选择python 3.10.6 […]
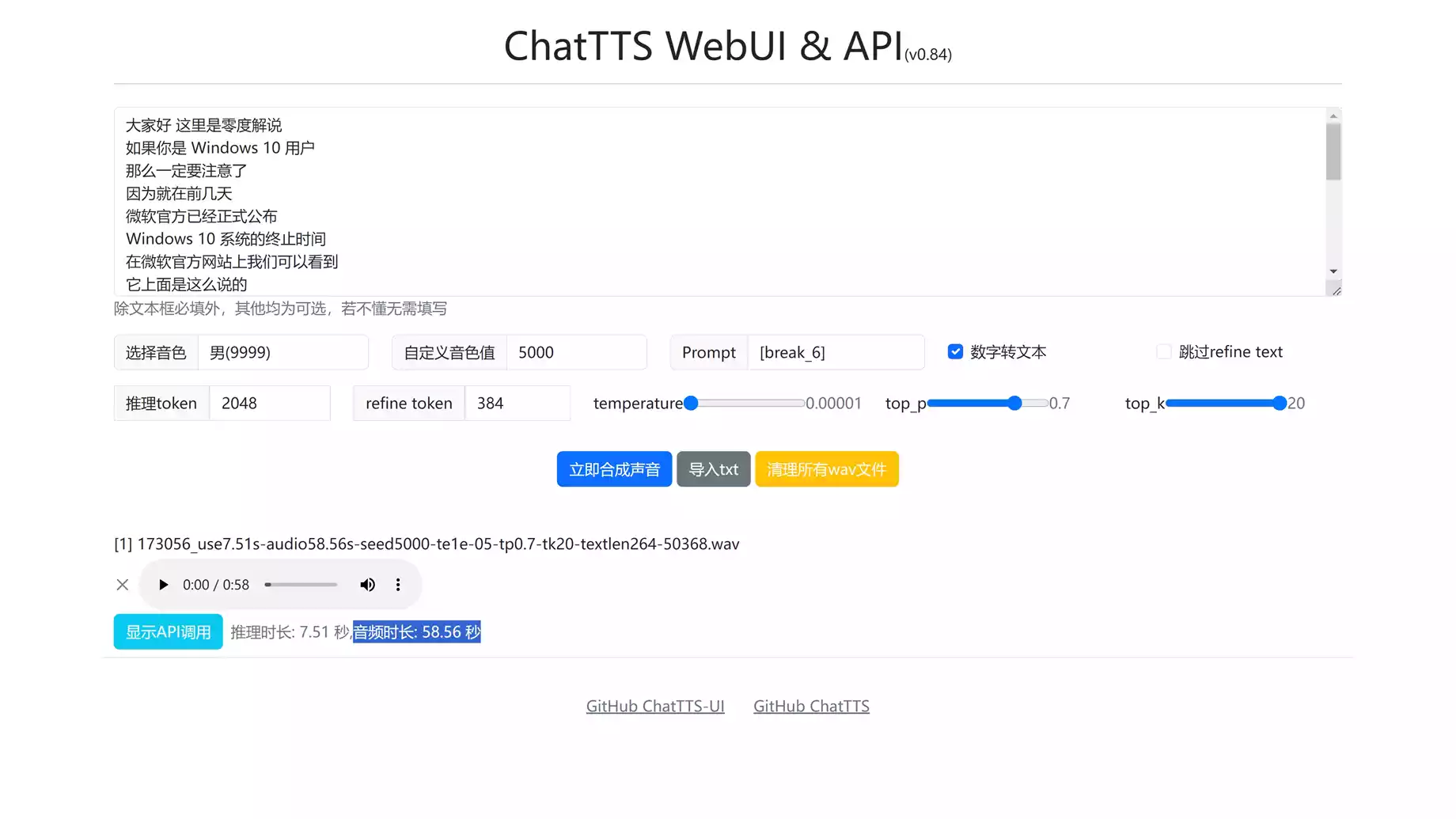
ChatTTS是专门为对话场景设计的文本转语音模型,例如LLM助手对话任务。它支持英文和中文两种语言。最大的模 […]
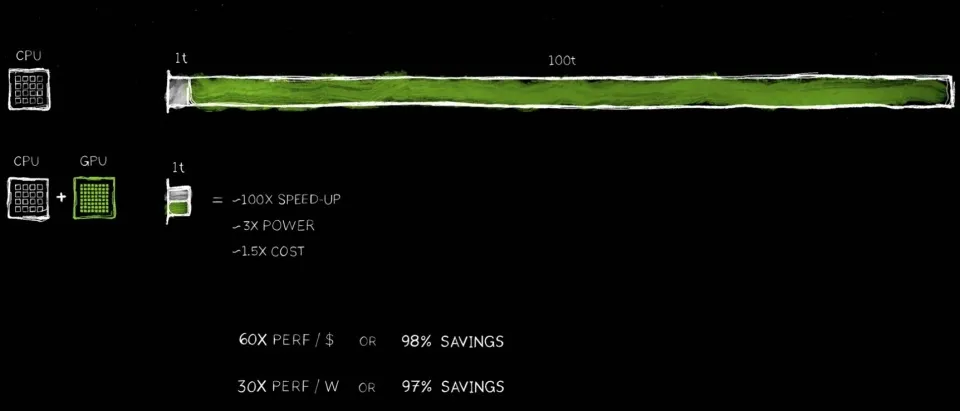
6月2日,英伟达联合创始人兼首席执行官黄仁勋在Computex 2024(2024台北国际电脑展)上发表主题演 […]
Video-MME(Multi-Modal Evaluation benchmark)是首个专门为评估多模态大 […]
NVIDIA最近发布了一套名为NVIDIA ACE的生成式AI微服务,这些服务旨在加速数字人(虚拟人)的发展。 […]
把自己变成了吉卜力电影角色🤩。这非常简单,只需40分钟!按照以下步骤操作即可。 使用Midjourney生成吉 […]
Sref Codes是什么? Midjourney风格参考种子(srefs)是代表不同风格的独特标识符,通常称 […]
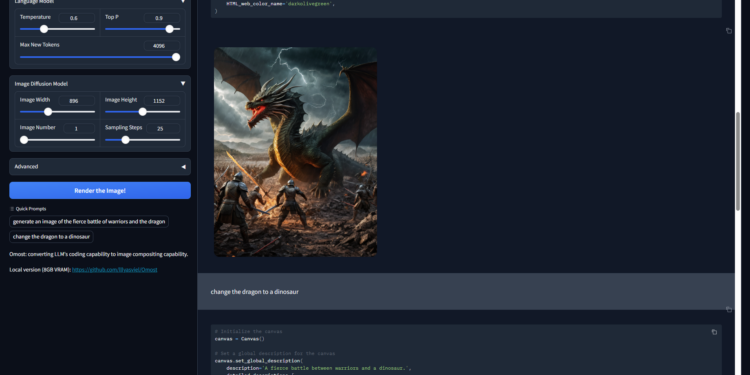
Omost 是一个使用大语言模型(LLM)生成图像的项目。它通过虚拟画布代理来合成图像,旨在将模型的代码能力转 […]
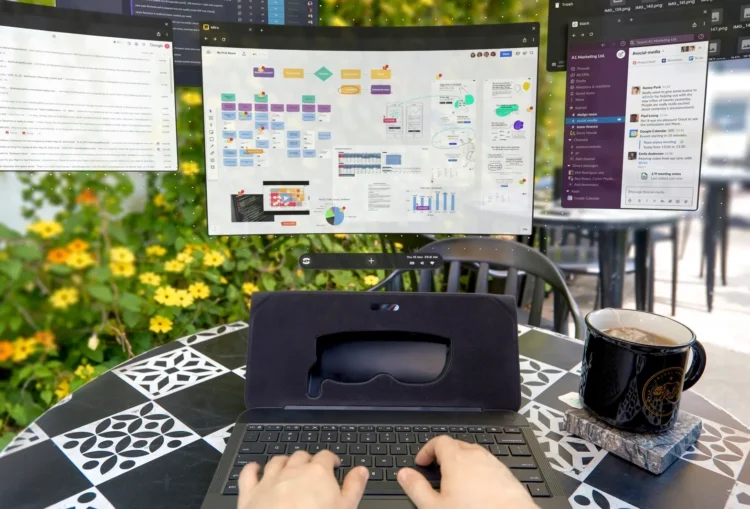
Spacetop 是一种革命性的笔记本电脑,它取消了传统的物理显示屏,取而代之的是使用 AR(增强现实)眼镜, […]
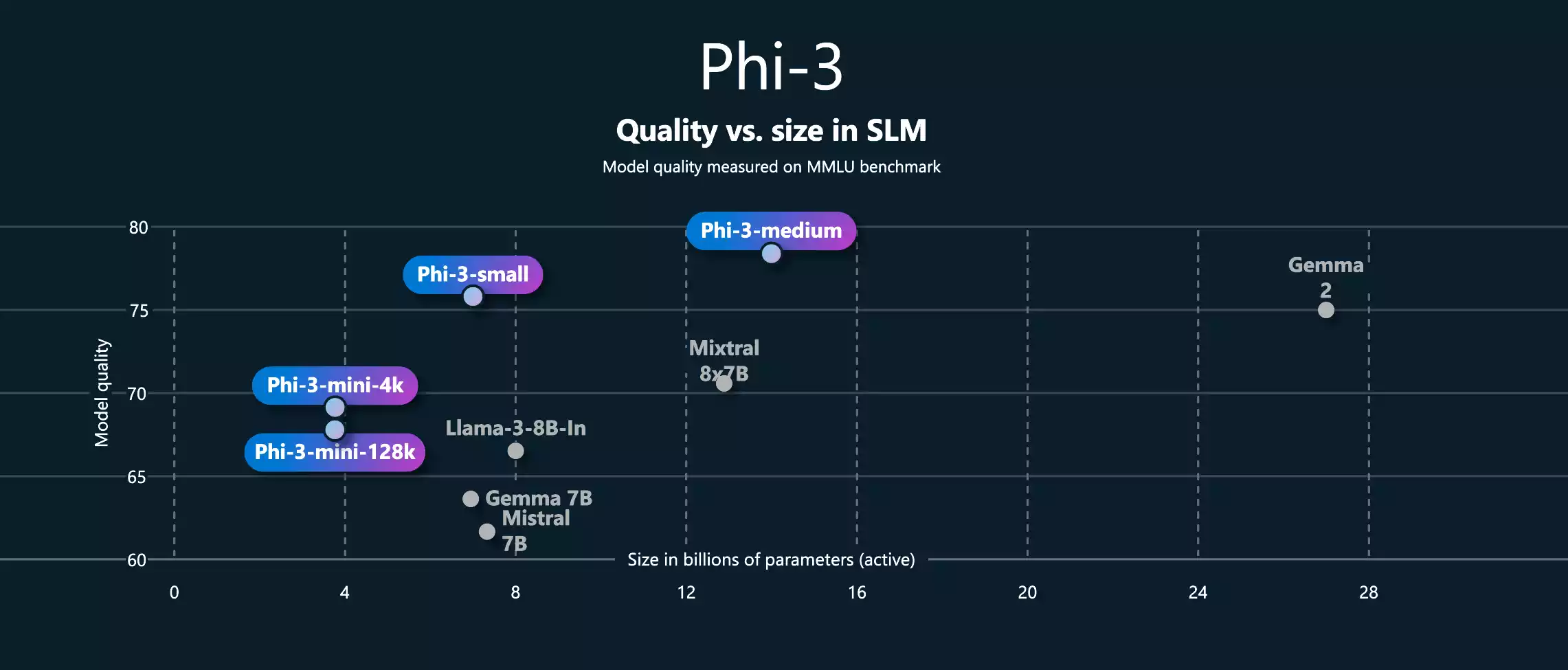
Phi-3 Mini Phi-3 Mini 是一个拥有 38 亿参数的轻量级、最先进的开放模型,使用 Phi […]
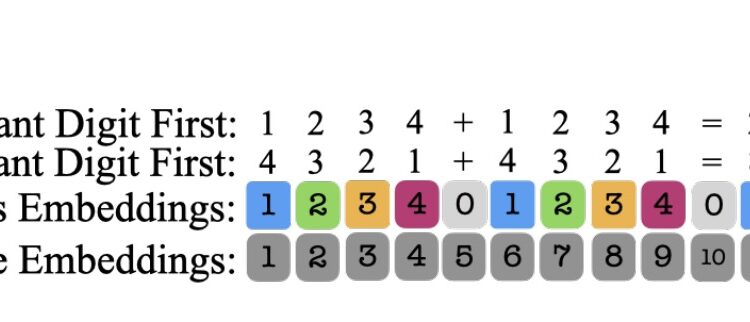
传统的transformer在处理长数字序列时,难以准确地跟踪和表示每个数字的位置,导致在进行多步骤和复杂运算 […]
Anthropic的Claude 3模型现在支持Tool use功能,可以与外部工具和API交互,执行各种任务 […]
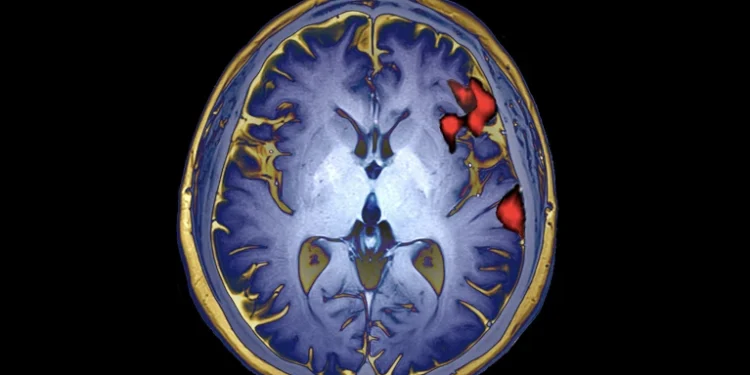
加州大学旧金山分校的研究人员刚刚开发出一种大脑植入物,研究人员成功地帮助一名失去说话能力的双语患者通过脑植入设 […]
Consistent Character 模型,结合多种技术实现角色的一致性图像生成,可以生成给定角色的不同姿 […]
ElevenLabs推出了一款新的AI音频模型,能够根据文本提示生成各种音效、短乐器曲目、音景和各种角色声音。 […]
影眸团队推出了Rodin Gen-13D生成AI模型。这个模型可以在几十秒内通过文本生成高质量的3D模型,这些 […]
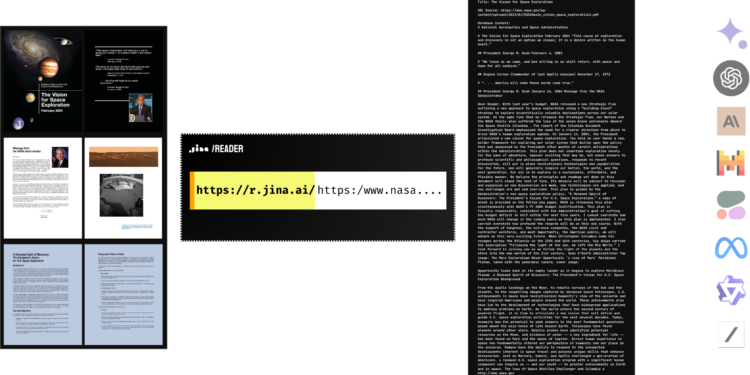
Jina AI 宣布其 Reader 工具现在能够从任意 URL 读取 PDF 文件,并快速解析成文本,供下游 […]
Sonic 是一个快速、超逼真的语音生成模型,专为实时互动语音而设计,基于下一代状态空间模型(State Sp […]
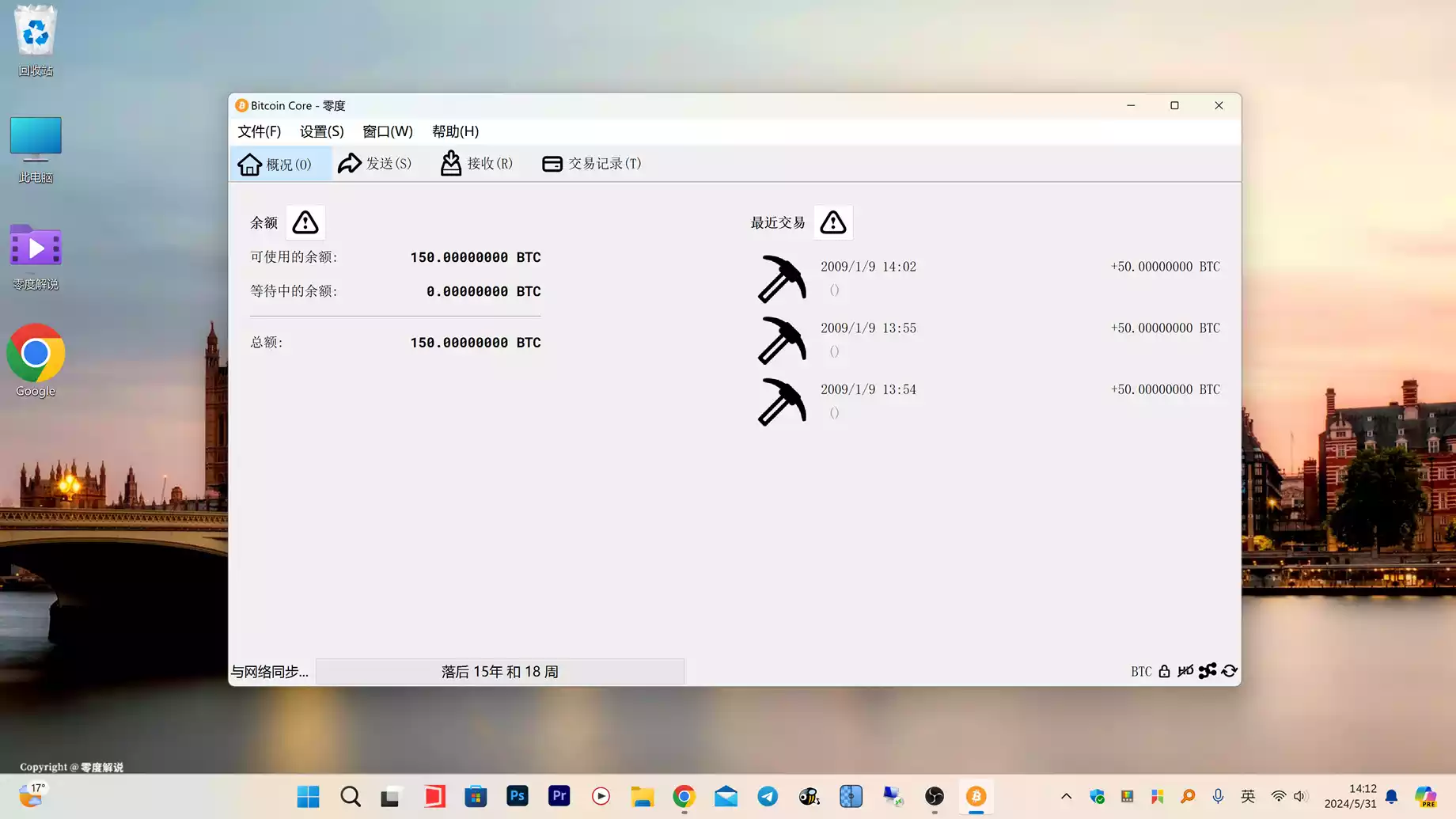
这是一个装有150多枚比特币的钱包,目前总价值1020万美金,100%真实!童叟无欺 150枚比特币的 […]
OpenAI推出了ChatGPT Edu,这是一个为大学设计的专用版本,旨在让学生、教职员工、研究人员和校园运 […]
Perplexity AI推出Perplexity Pages ,该工具可以帮助你把你搜到的答案自动转化为视觉 […]
ToonCrafter 是一个帮助动画师生成和优化卡通动画过渡效果的工具。解决了卡通动画中帧与帧之间过渡不自然 […]
V-Express 是由南京大学和腾讯AI实验室共同开发的一项可以把单张照片变成视频的技术,并且它能够根据不同 […]
Udio推出新的udio-130音乐生成模型,可以生成2分钟的音频,帮助创建更具连贯性和结构的曲目。 这意味着 […]
















我需要一些适合父亲旅行的父亲节礼物建议,例如行李箱、旅行背包、户外装备等。 父亲节即将来临,我想为爸爸准备一份 […]