首页 > Ai资讯
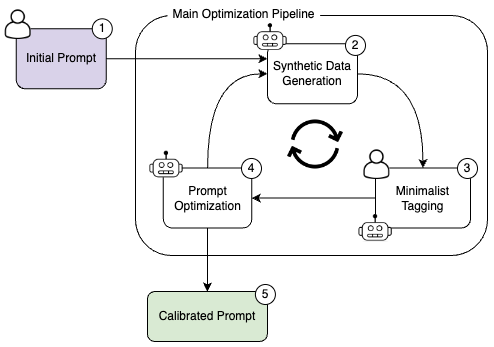


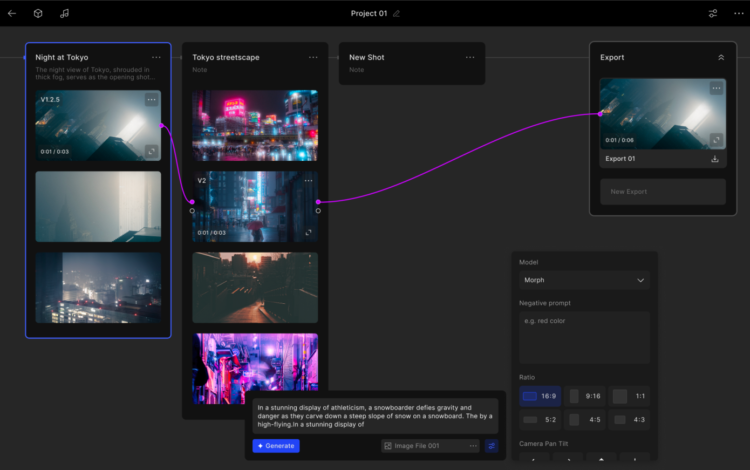
Morph Studio:将Stability AI生成的视频片段编织成一部电影
Morph Studio最近引入了一个创新的工具,允许用户将Stability AI生成的视频片段编织成一部电 […]
















该项目由阿里巴巴开发,利用单张图像和音频输入(如说话或唱歌),EMO能够生成具有表情变化和头部动态的虚拟人像视 […]