首页 > Ai资讯


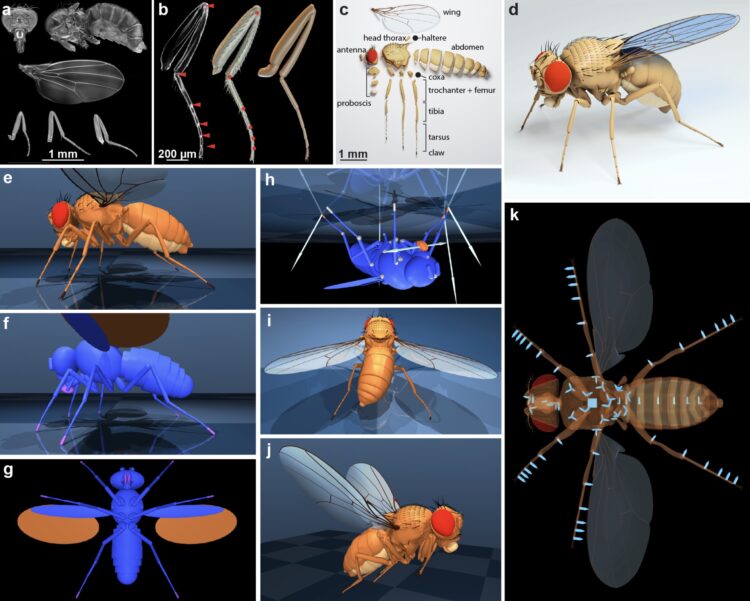














AnimateDiff-Lightning:快如闪电的视频生成模型 速度提升十倍
字节跳动的AnimateDiff-Lightning发布 AnimateDiff-Lightning能够更快地 […]








在2021年夏天,OpenAI宣布关闭其机器人团队,原因是缺乏必要的数据来训练机器人如何使用人工智能进行移动和 […]