“Tool use (function calling)是Claude一个特定功能,允许它与外部客户端工具和函 […]
这篇论文展示了语言模型(LMs)可以通过吸收(即融合)来自同源模型的参数来获得新的能力,这个过程不需要重新训练 […]
Lixel CyberColor (LCC) 是由 XGRIDS 公司开发的一款先进技术产品,旨在自动生成大规 […]
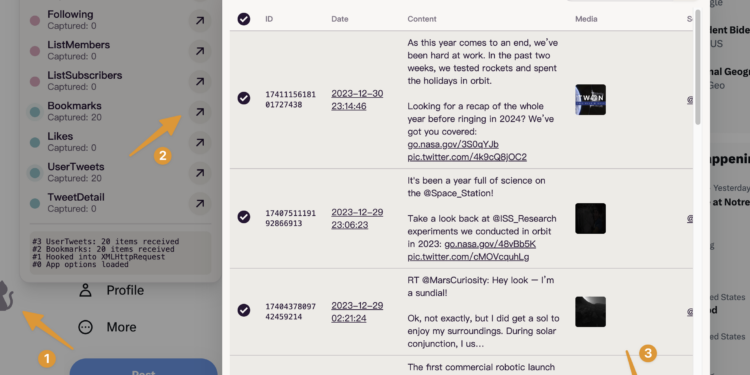
Twitter-web-exporter:一键导出推文、书签、列表 一个开源工具,可以直接在浏览器运行。 […]
Anthropic Cookbook是一个开源项目,收集了一些有趣且有效的方法来教你使用Claude。这个项目 […]
Clarity AI是一个AI图像放大与增强的工具,提供了一个免费和开源的Magnific替代方案。 主要特点 […]
在制作3D动画角色时,除了角色的形状和结构(我们称之为几何设计)之外,角色的外观、颜色和纹理(即角色的皮肤和衣 […]
Chinese Tiny LLM:从头开始训练 专注于中文的大语言模型 CT-LLM是针对中文设计的首个大 […]
StructLDM项目是由南洋理工大学开发的一个先进的3D人体生成技术。它能够根据2D图像的学习,自动生成3D […]
Hand Talk App:利用人工智能自动将文本和音频翻译成美国手语(ASL)和巴西手语(Libras)。这 […]
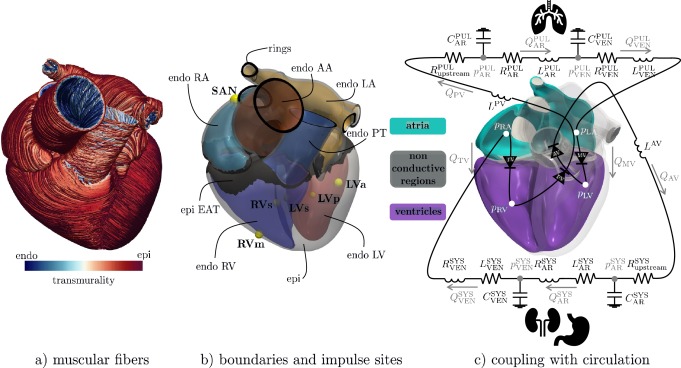
这项研究开发了一种复杂的计算模型,用以模拟整个人类心脏的血液动力学,即心脏内血流的流动和变化。这个模型特别的地 […]
Google介绍了一种新型的视频字幕生成方法,专门用于处理视频中的密集事件并为其生成字幕。这种方法的亮点在于它 […]
创建角色表是一种既简单又强大的方法,可以用于各种目的,包括角色信息收集、故事板制作、新工作流程宣布以及测试角色 […]
WhisperKit是一个Swift包,它将OpenAI流行的Whisper语音识别模型与Apple的Core […]
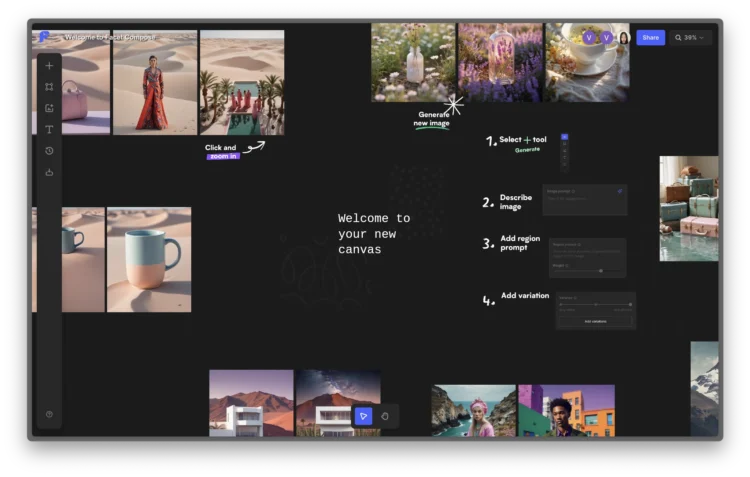
Facet是一个专为创意专业人士设计的协作AI图像生成和编辑工具,提供了强大的图像合成能力。 它结合了直观的画 […]
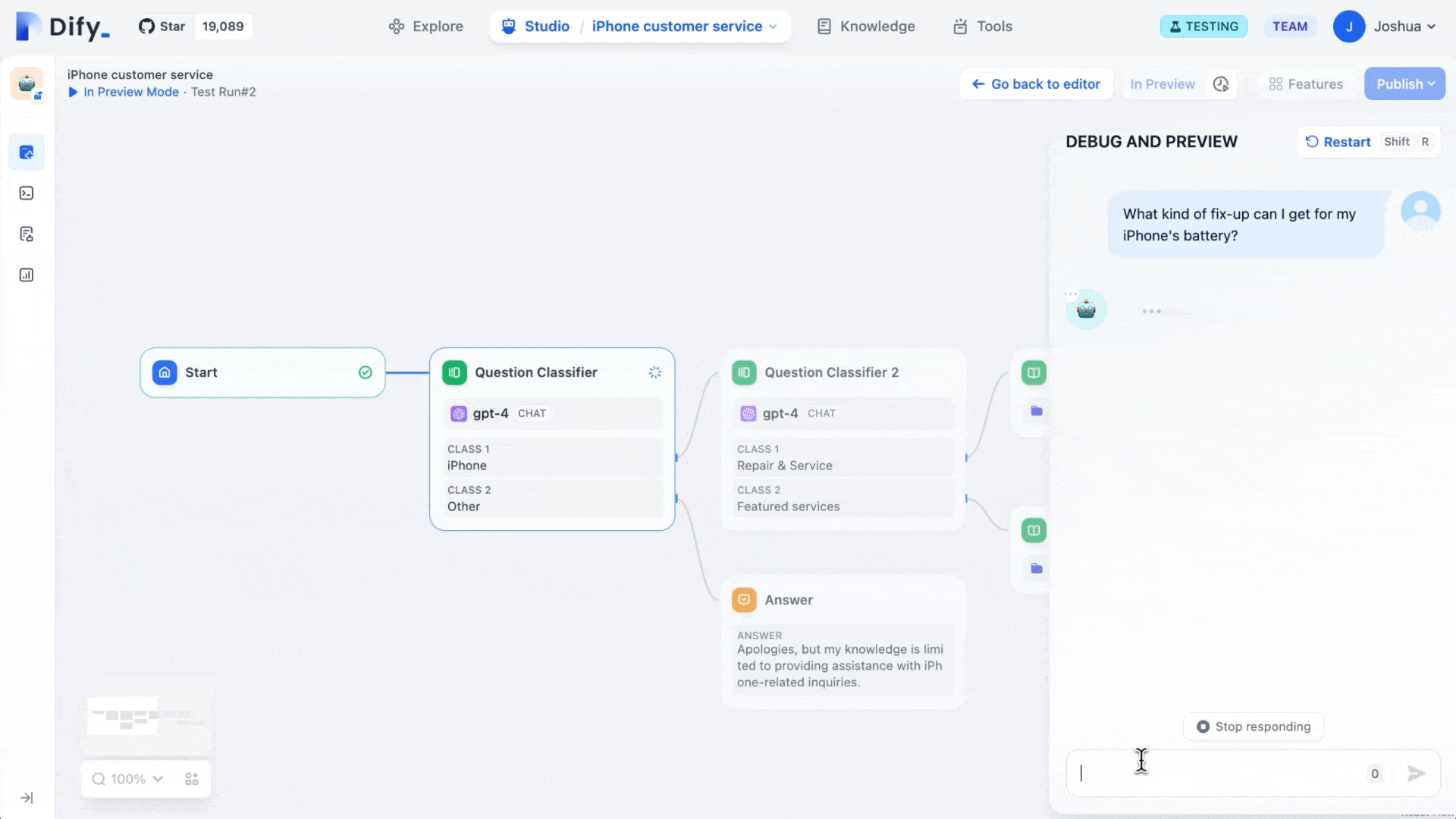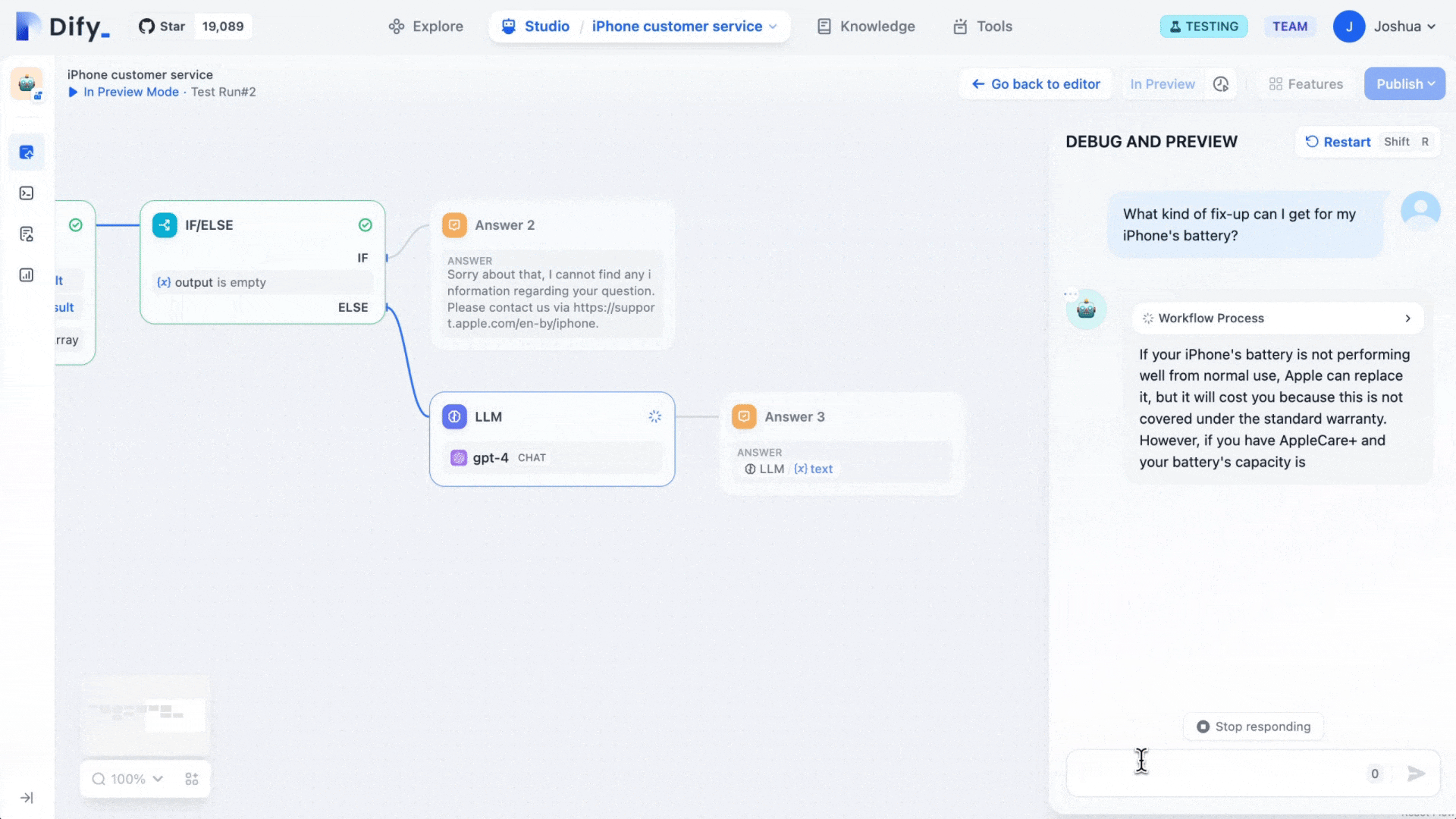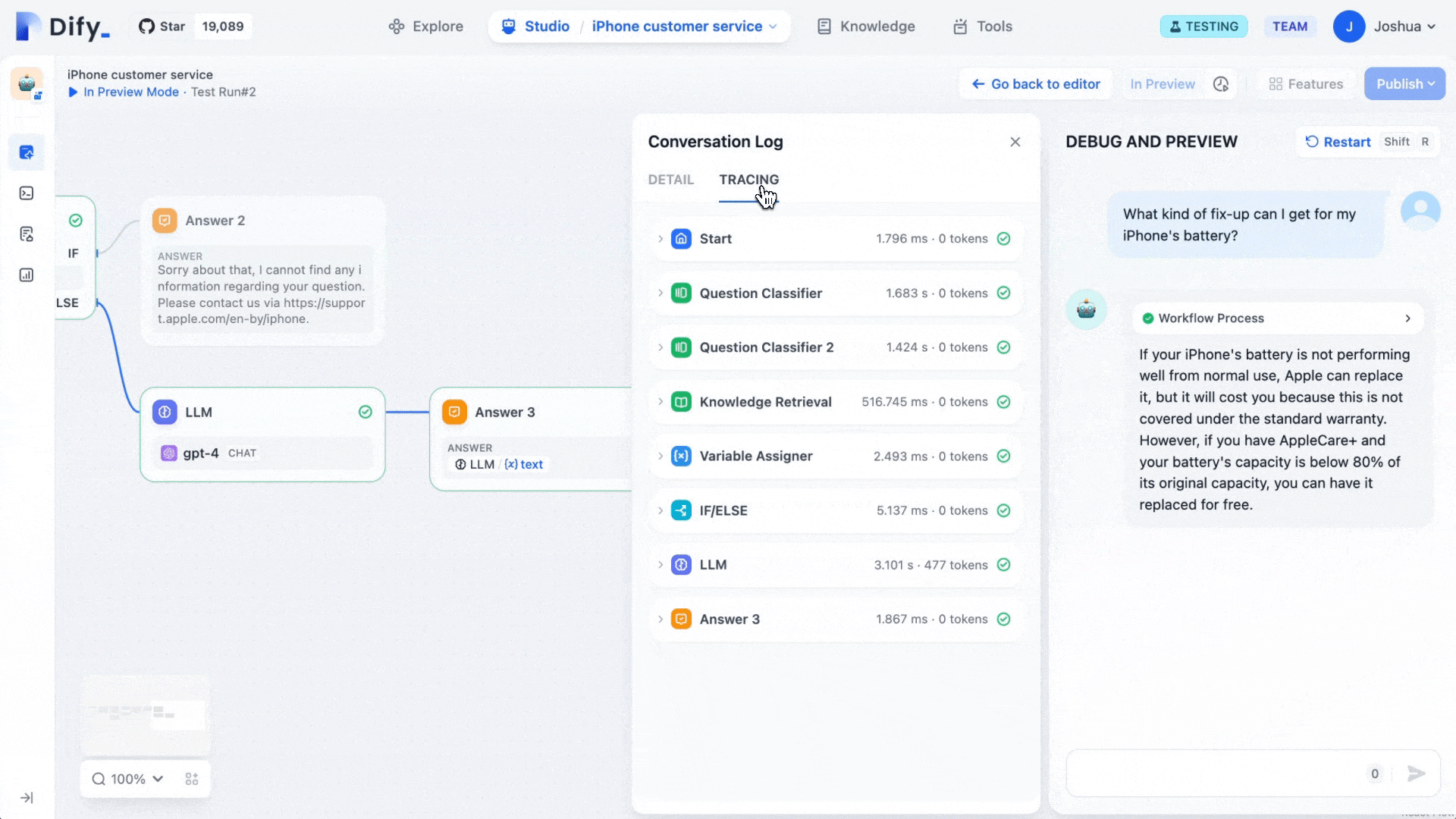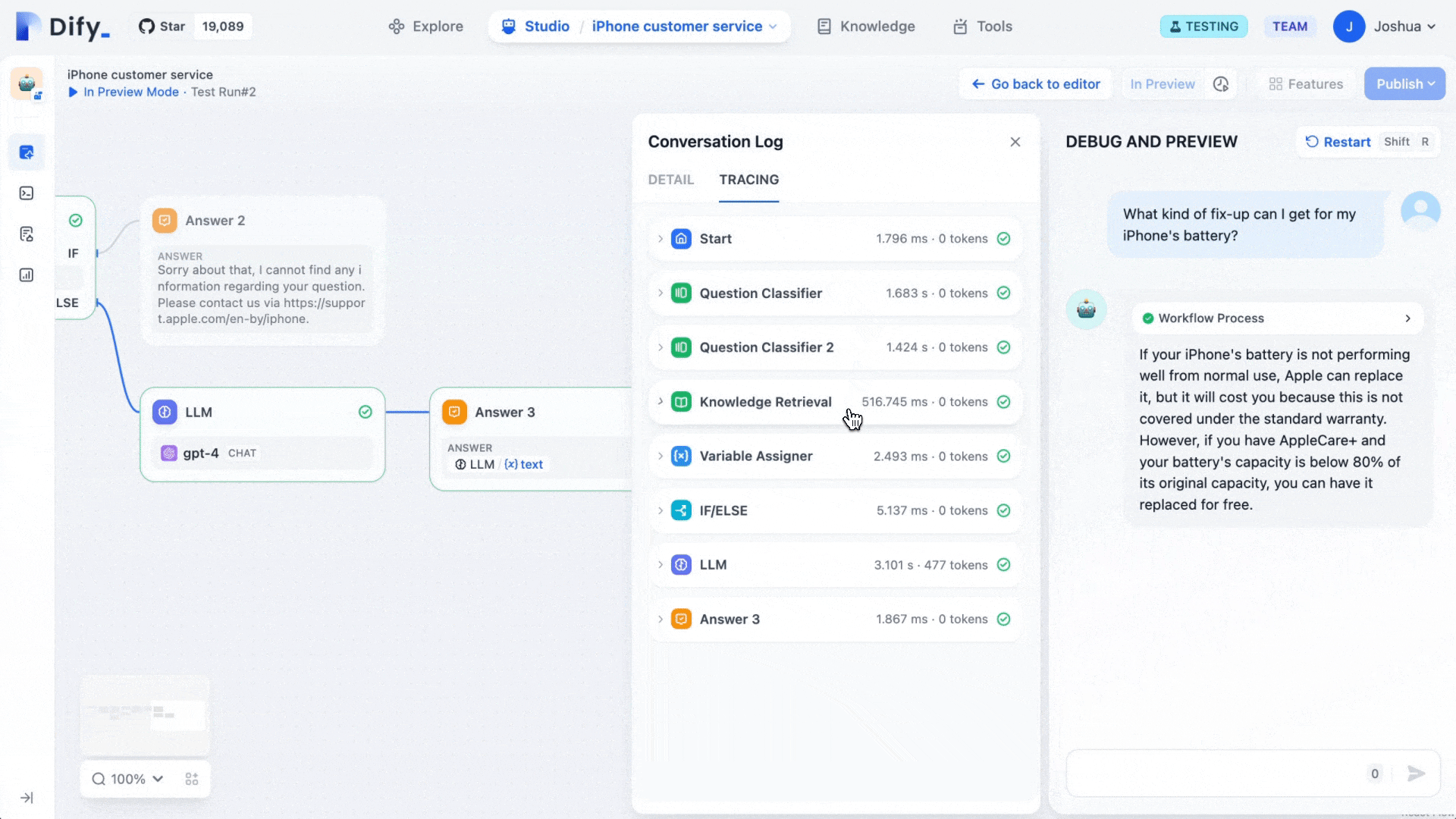
Dify Workflow 是一种新推出的 AI 工作流程工具,旨在帮助大语言模型(LLMs)的应用能更好地落 […]
Spotify 推出了一个名为 AI 播放列表的新功能,该功能处于测试阶段,允许用户基于书面提示生成播放列表。 […]
Transformer-Lite是一款专为移动设备设计的推理引擎,由OPPO AI研究中心开发,它旨在将大语言 […]
Ferret-UI是由苹果开发的一个专门理解和与移动用户界面(UI)互动的多模态大语言模型(MLLM)。 它把 […]
DreamWalk:利用扩散引导技术进行风格空间的探索,能够在图像生成中实现对风格和内容的精细控制。 它主要针 […]
DesignEdit是一个先进的图像编辑研究项目,旨在通过多层次潜在分解与融合技术实现统一且精确的图像编辑。这 […]
Google 宣布 Gemini 1.5 Pro 开放API 现已在180多个国家提供 新增对原生音频(语音) […]
OpenAI 发布了GPT-4-Turbo 正式版 带有视觉能力,上下文 128k 主要信息包括: ▶ 全面开 […]
MagicTime:是一个专注于生成变形时间延迟视频的模型,集成DiT-based架构,解决了现有文本到视频( […]
Google发布Gemma 系列的新成员,这是一系列针对开发者和研究者设计的轻量级、最先进的开放模型,建立在创 […]
HairFastGAN,一个解决将参考图像中的发型转移到输入照片上以进行虚拟发型试戴的复杂任务的新方法。它能够 […]
Parler-TTS 是一个由 Hugging Face 开发的轻量级文本转语音(TTS)模型,能够以给定说话 […]
LLocalSearch 是一个完全本地运行的搜索聚合器,使用LLM Agents。用户可以提出一个问题,系统 […]
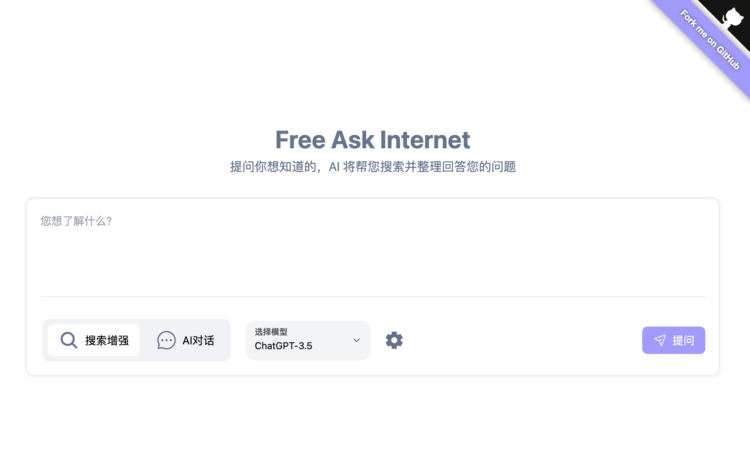
FreeAskInternet 是一个开源项目,提供了一个完全免费、私密且本地运行的类似perplexity. […]
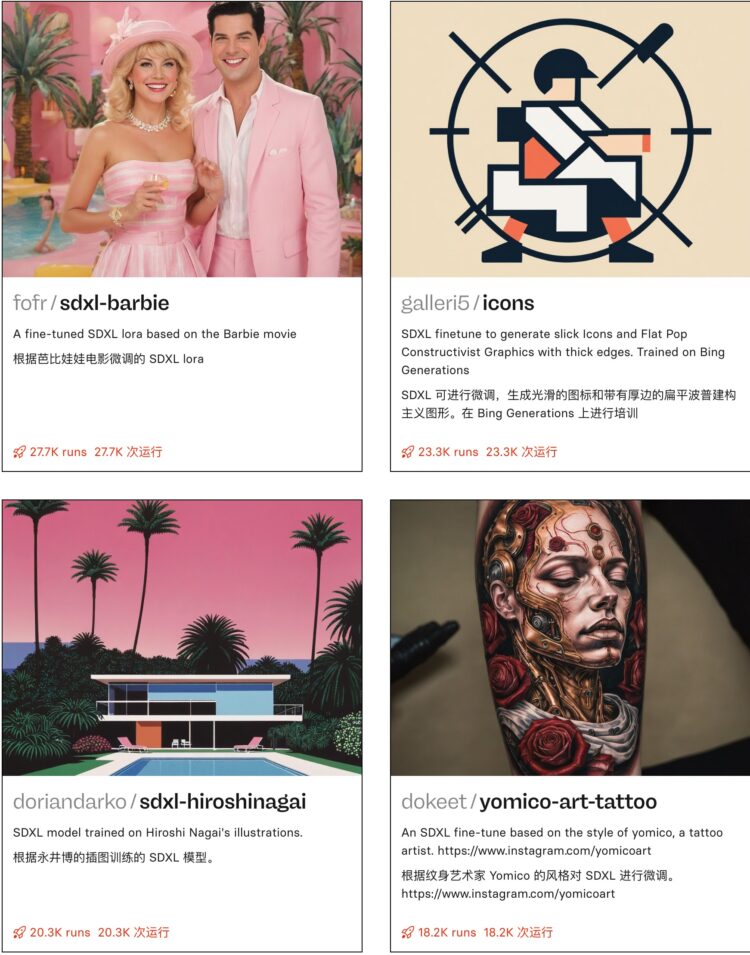
Replicate上的“SDXL fine-tunes”收藏包含了一系列基于SDXL模型的精选微调模型。这些微 […]























“Tool use (function calling)是Claude一个特定功能,允许它与外部客户端工具和函 […]