Google开发出一种名为“Infini-attention”的新型注意力技术,旨在有效扩展基于Transfo […]
Udio是什么 UdioUdio 由前谷歌 DeepMind 的领先 AI 研究员和工程师创立,得到 a16z […]
第六届福布斯人工智能 50 强榜单展示了从 1900 家申请公司中评选出的顶级人工智能公司,彰显了该行业的发展 […]
DreamWorld AI:他们的专有AI模型和算法允许用户无需穿戴特殊的装备或使用追踪标记,仅需单镜头摄像设 […]
Warning: Attempt to read property "child" on null in /v […]
SceneScript 是由 Meta Reality Labs Research 开发的一种新型 3D 场景 […]
Ideogram.ai 最近发布了其文本到图像模型 Ideogram 1.0 的一次重大升级。这次更新不仅改进 […]
Cohere 最近推出了其最新的基础模型 Rerank 3,专为提升企业搜索和检索增强生成(RAG)系统而设计 […]
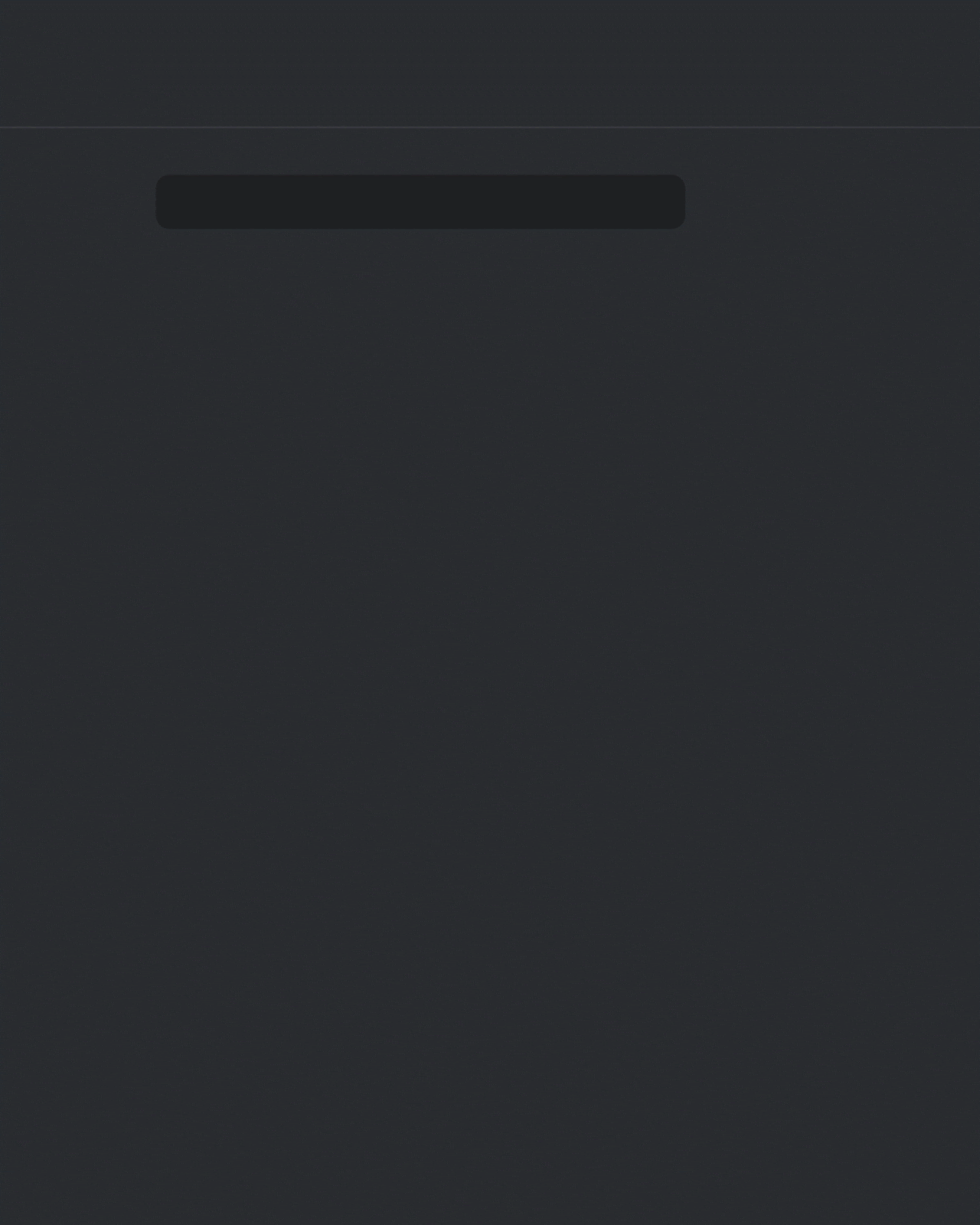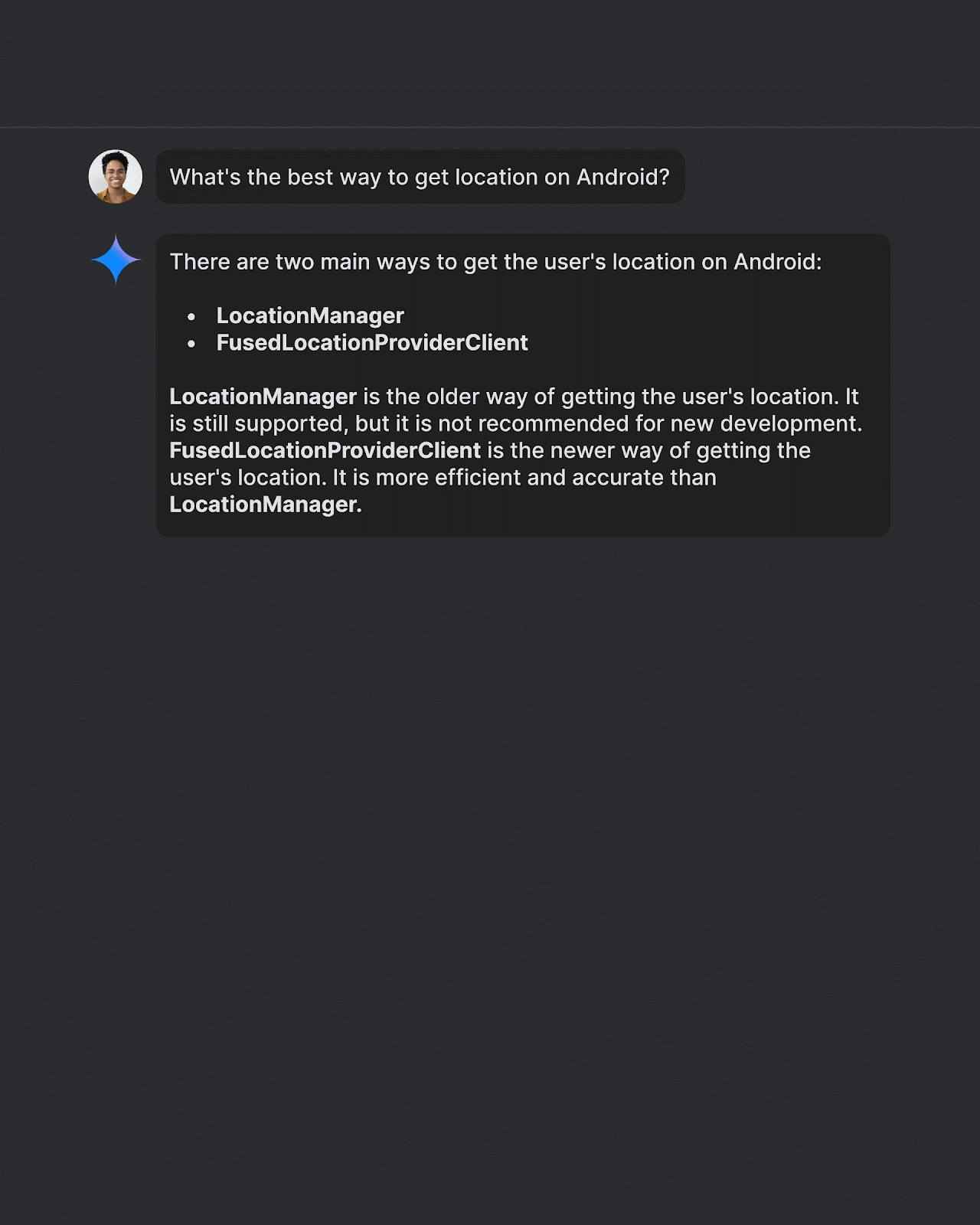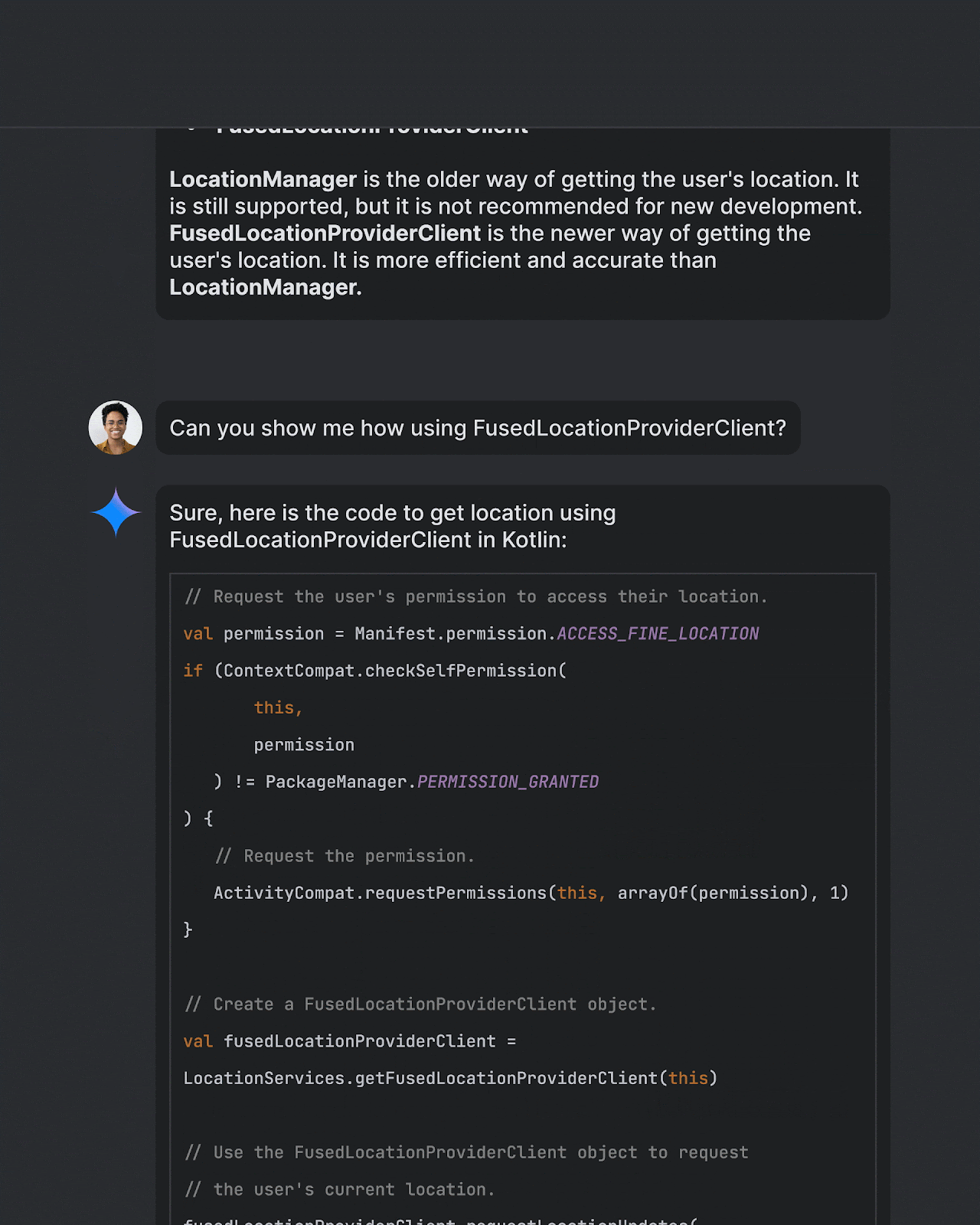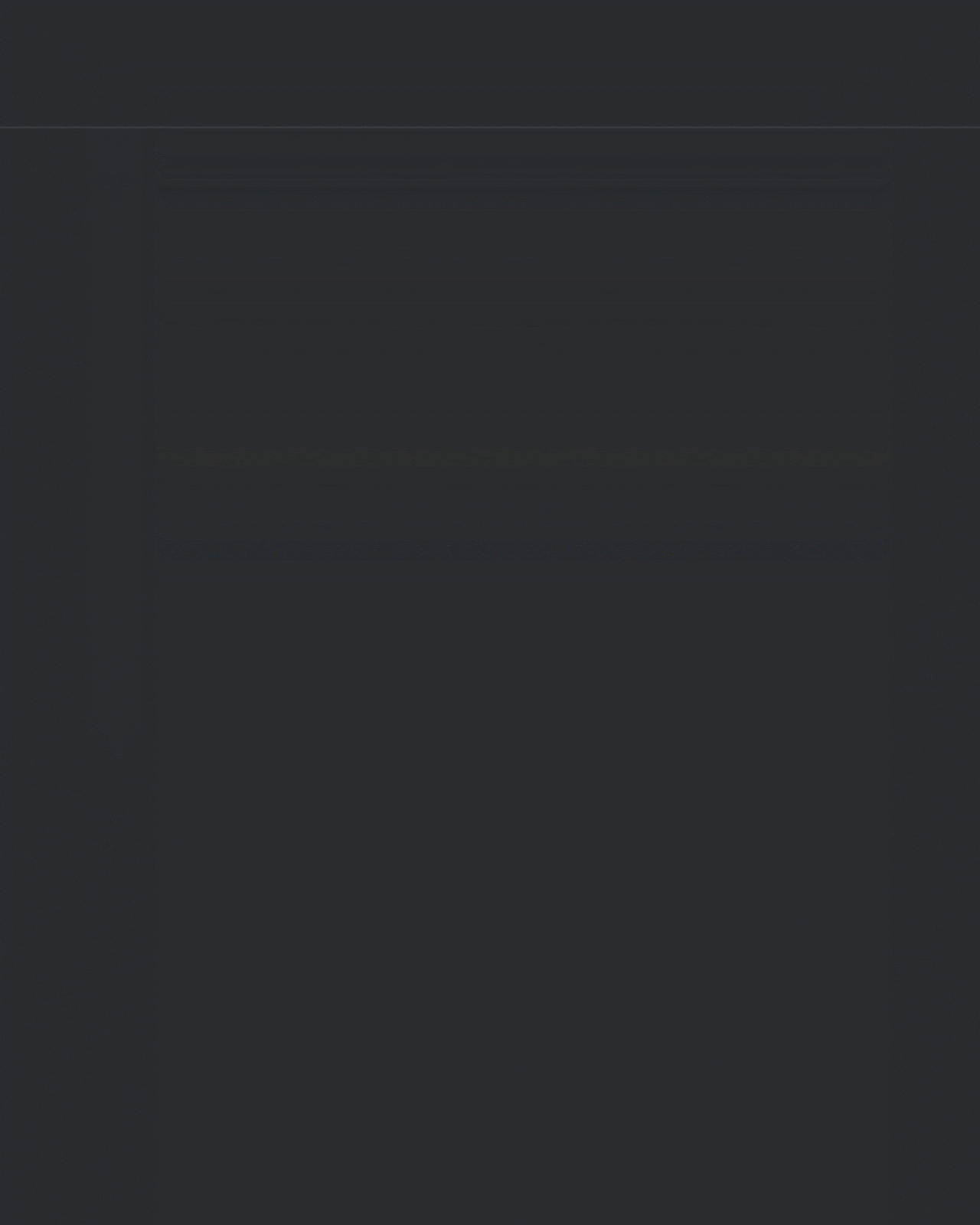
Android Studio 是 Google 官方推出的集成开发环境(IDE),专门为 Android 应用 […]
该项目为马里兰大学帕克分校和 Facebook AI 的研究人员,关于现实世界中对对象检测器的对抗性攻击研究。 […]
马斯克X AI发布Grok-1.5 Vision 多模态模型 Grok-1.5V能够处理文本以及各种视觉信息, […]
ScreenAI 是Google Research开发的一款视觉语言模型,专门针对用户界面(UI)和信息图的理 […]
Archetype AI 发布了一个创新的人工智能平台 —— Newton™,这是一个专门为理解物理世界设计的 […]
清华大学电子工程系卢芳副教授和自动化系戴琼海教授团队设计出一种基于光子技术而非传统电子晶体管的革命性人工智能( […]
Xiaohu.AI 会员权益 Xiaohu.AI 是什么 Xiaohu.AI 是有小互建立的一个专门发布AI资 […]
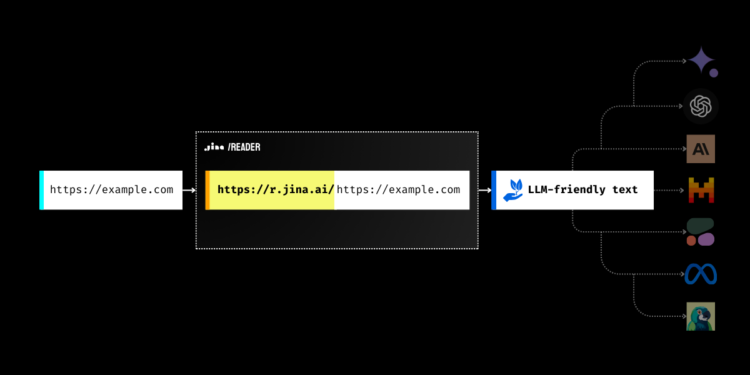
jina-ai/reader 将任何网页URL转换为大语言模型(LLM)友好的输入格式。它通过一个简单的前缀 […]
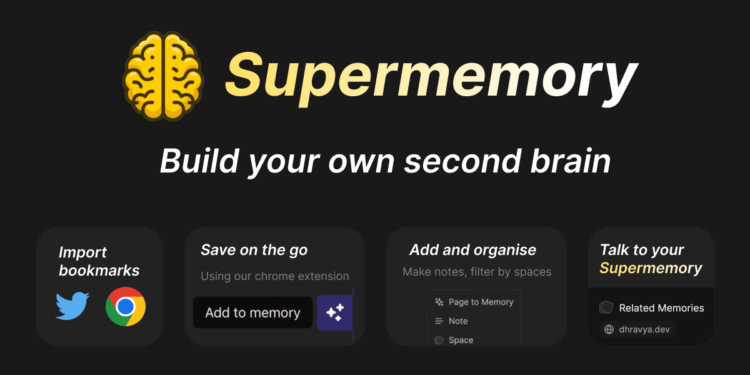
supermemory 的主要作用是帮助用户构建一个“第二大脑”,通过一个简单的Chrome扩展,用户可以保存 […]
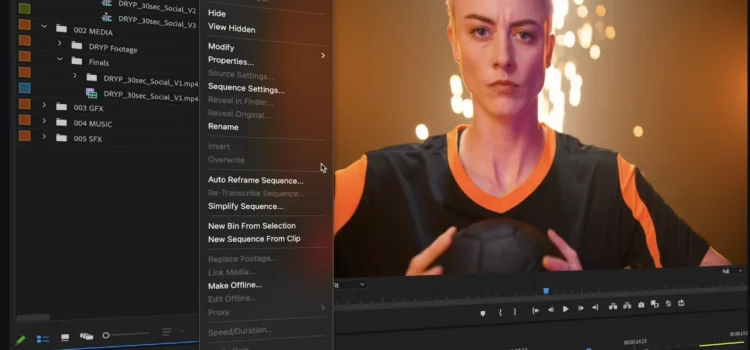
Adobe Premiere Pro 正在引入 AI 工具以简化视频编辑工作流程,减少完成繁琐任务的时间。 其 […]
Rewind公司正式推出之前他们展示可穿戴吊坠AI设备:Limitless Limitless可以作为项链 […]
2txt:Image to text 图像转文字 使用Claude Haiku 和@vercel AI S […]
2024年的人工智能指数报告是迄今为止最全面的一次,涵盖了AI技术进步、公众对AI的看法以及AI发展的地缘政治 […]
Cohere推出其最新的基础嵌入模型Compass的私人测试版。Cohere Compass 是一个基础嵌入模 […]
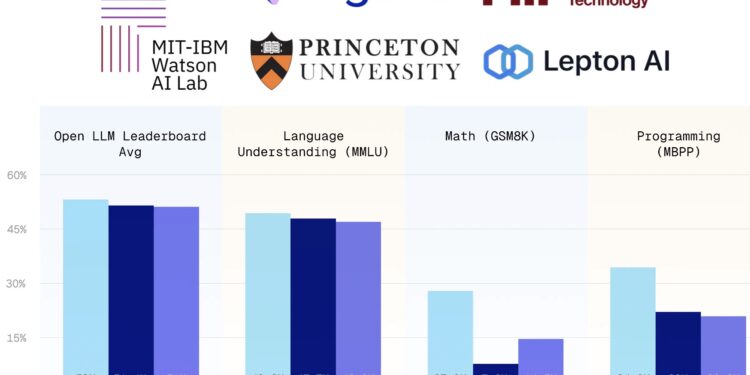
JetMoE-8B 是一个高性能的大语言模型,它以不到10万美元的成本训练,性能超过了Meta AI的LLaM […]
该论文的主要研究目的是利用生成式人工智能(AI)技术,通过创建和分析一个大规模的知识图谱来加速科学发现。研究团 […]
CTRL-F-VIDEO 是一个开源项目,使用户能够在视频中搜索特定的单词或短语。 这个项目主要针对YouTu […]
Reka AI推出了其最大、最强大的多模态语言模型——Reka Core。Core能够处理文本、图像、视频和音 […]
Javi Lopez展示了如何将一幅简单的手绘草图在7分钟内转变为精美的图画甚至是3D渲染效果。他首先快速完成 […]
ZeST(Zero-Shot Material Transfer)是一种从单一图像进行材质迁移的方法。该技术能 […]
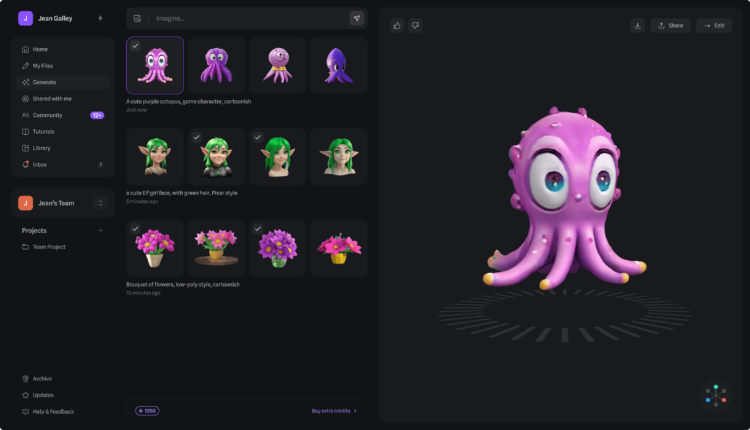
Spline 推出一个免费的3D设计工具:AI 3D Generation,可以帮助用户快速生成三维模型的工具 […]
InstantMesh 是一个使用前馈框架的技术,它能够从单张图像快速生成高质量的三维网格模型。这个框架结合了 […]






















Google开发出一种名为“Infini-attention”的新型注意力技术,旨在有效扩展基于Transfo […]